01-15 Simulation & Sampling#
Partially adapted from Statisical Thinking for the 21st Century
Today we’re going to discuss the “4 horsemen” of modern computational statistics:
Monte-carlo simulation
Bootstrapping
Permuting
Cross-validation
Building strong intuitions about these concepts will enable you to make inferences and reason about any statistical analysis or model you do in the future!
If you want to enjoy a funny youtube video (~40min) that partly inspired this notebook, I highly recommend watching Statistics for Hackers by Jake VanderPlas. Jake is one of my personal inspirations - a computational astrophysicist by training - but huge contributor and educator for the open-source scientific Python community.
Introduction#
The use of computer simulations has become an essential aspect of modern statistics. For example, one of the most important books in practical computer science, called Numerical Recipes, says the following:
“Offered the choice between mastery of a five-foot shelf of analytical statistics books and middling ability at performing statistical Monte Carlo simulations, we would surely choose to have the latter skill.”
In other words:


Simulation: The Monte Carlo method#
The concept of Monte Carlo simulation was devised by the mathematicians Stan Ulam and Nicholas Metropolis, who were working to develop an atomic weapon for the US as part of the Manhattan Project. They needed to compute the average distance that a neutron would travel in a substance before it collided with an atomic nucleus, but they could not compute this using standard mathematics. Ulam realized that these computations could be simulated using random numbers, just like a casino game.
In a casino game such as a roulette wheel, numbers are generated at random; to estimate the probability of a specific outcome, one could play the game hundreds of times. Ulam’s uncle had gambled at the Monte Carlo casino in Monaco, which is apparently where the name came from for this new technique.

There are four steps to performing a Monte Carlo simulation:
Define a domain of possible values
Generate random numbers within that domain from a probability distribution
Perform a computation using the random numbers
Combine the results across many repetitions
Example#
As an example, let’s say that I want to figure out how much time to allow for an in-class quiz. We will pretend for the moment that we know that the distribution of quiz completion times is normal, with mean of 5 minutes and standard deviation of 1 minute.
Given this, how long does the test period need to be so that we expect all students to finish the exam 99% of the time?
There are two ways to solve this problem. The first is to calculate the answer using a mathematical theory known as the statistics of extreme values. However, this involves complicated mathematics. Alternatively, we could use Monte Carlo simulation.
To do this, we need to simulate random samples from a normal distribution.
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(0) # for reproducibility
num_students = 30
quiz_times = np.random.normal(loc=5, scale=1, size=num_students)
plt.hist(quiz_times);
plt.xlabel('Time (minutes)');
plt.ylabel('Count');
plt.title(f"Quiz times for {num_students} students\nMean: {np.mean(quiz_times):.2f} minutes");
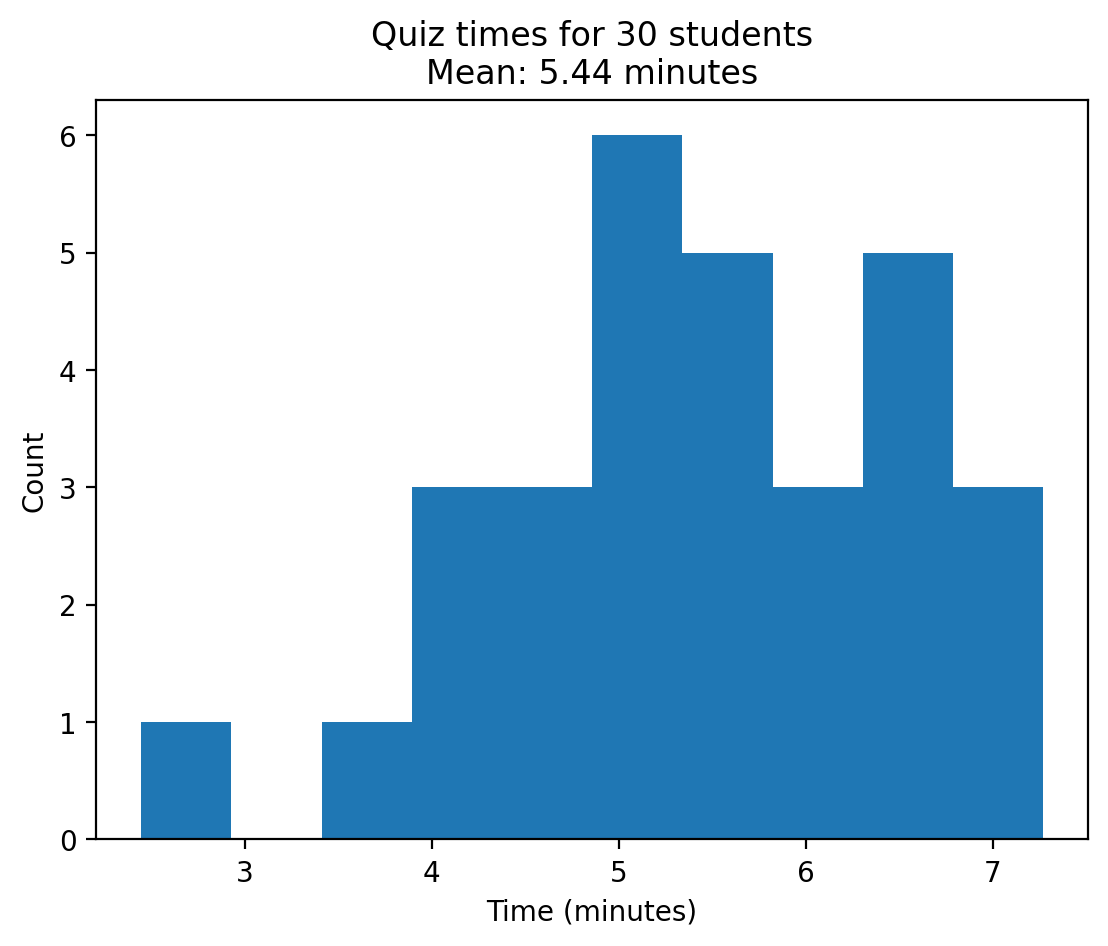
Now, say that I administer 3 quizzes and record the finishing times for each student for each exam, which might look like the distributions presented here:
np.random.seed(0) # for reproducibility
fig, axs = plt.subplots(1,3, figsize=(12,4))
for idx, ax in enumerate(axs):
finishing_times = np.random.normal(loc=5, scale=1, size=100)
_ = ax.hist(finishing_times)
_ = ax.set_title(f'Quiz {idx+1}')
fig.supxlabel('Time (minutes)');
fig.supylabel('Count');
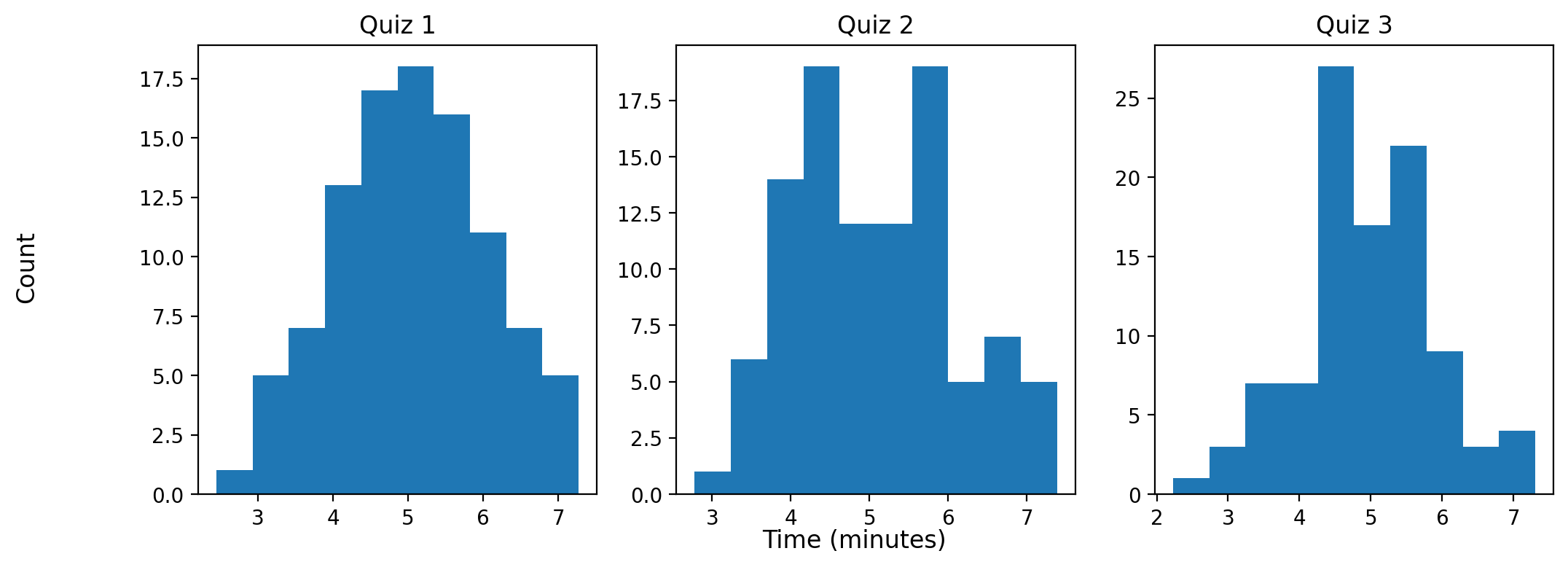
Each simulated quiz of students assumes a normal distrubition. But what we really want to know to answer our question is not what the distribution of finishing times looks like, but rather what the distribution of the longest finishing time for each quiz looks like.
To do this, we can:
Simulate the finishing times for a quiz, assuming a normal distribution
Record the longest finishing time for that quiz
Repeat a large number of times.
Plot the simulated distrubtion of longest finishing times, across the number of quizzes simullated
This will give us a distrubution of the maximimum quiz times, under the assumption that the finishing times of each quiz are normally distributed.
nsim = 5000
max_finishing_times = []
np.random.seed(0) # set seed for reproducibility
for sim in range(nsim):
finishing_times = np.random.normal(loc=5, scale=1, size=100)
max_finishing_times.append(finishing_times.max())
perc_99 = np.percentile(max_finishing_times, 99)
plt.hist(max_finishing_times);
plt.axvline(x=perc_99, color='red');
plt.xlabel('Max finishing time');
plt.ylabel('Count');
plt.title(f"99th percentile = {perc_99:.2f}");
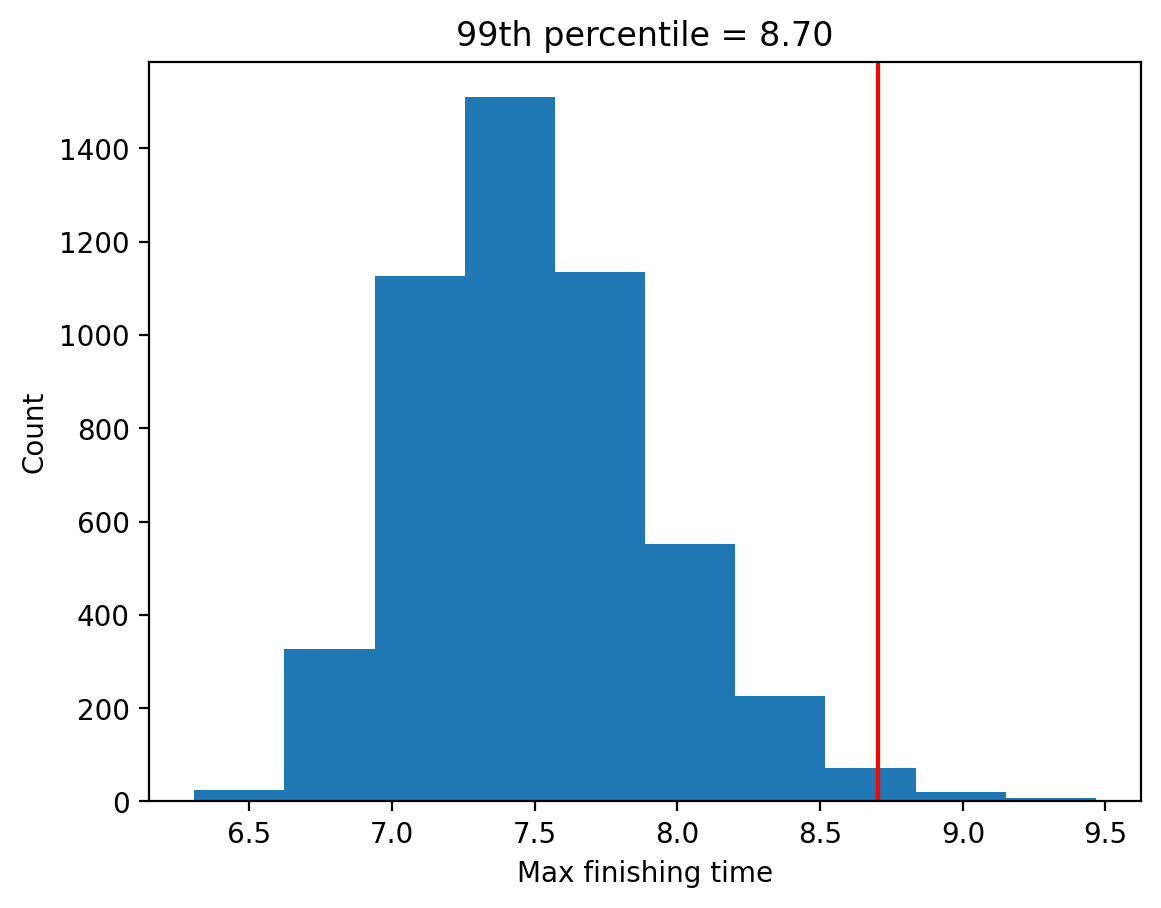
This shows that the 99th percentile of the finishing time distribution falls at ~8.7, meaning that if we were to give that much time for the quiz, then everyone should finish 99% of the time.
Take-aways#
When using simulation methods, always important to remember that our assumptions matter. If they are wrong, then the results of the simulation are useless.
In this case, we assumed that the finishing time distribution was normally distributed with a particular mean and standard deviation; if these assumptions are incorrect (and they almost certainly are, since it’s rare for elapsed times to be normally distributed), then the true answer could be very different!
Monte Carlo simulation methods show up in tons of domains of science and engineering, particularly when we’re trying to reason about things with uncertainty.
It allows us to move from the reasoning with logic and natural language in the abstract, to reasoning with numbers and figures in the concrete.

Bootstrap: Re-sampling with replacement#
Above, we made assumptions about what type of distribution we expect the sampling distribution to look like ahead of time (normally distributed)
But what if we can’t assume that the estimates are normally distributed, or we don’t know their distribution?
The idea of the bootstrap is to use the data themselves to estimate an answer. The name comes from the idea of pulling one’s self up by one’s own bootstraps, expressing the idea that we don’t have any external source of leverage so we have to rely upon the data themselves. The bootstrap method was conceived by Bradley Efron of the Stanford Department of Statistics, who is one of the world’s most influential statisticians.
The idea behind the bootstrap is that we repeatedly sample from the actual dataset; importantly, we sample with replacement, such that the same data point will often end up being represented multiple times within one of the samples. We then compute our statistic of interest on each of the bootstrap samples, and use the distribution of those estimates as our sampling distribution.
In a sense, we treat our particular sample as the entire population, and then repeatedly sample with replacement to generate our boot-strapped samples for analysis. This makes the assumption that our particular sample is an accurate reflection of the population, which is probably reasonable for larger samples but can break down when samples are smaller.
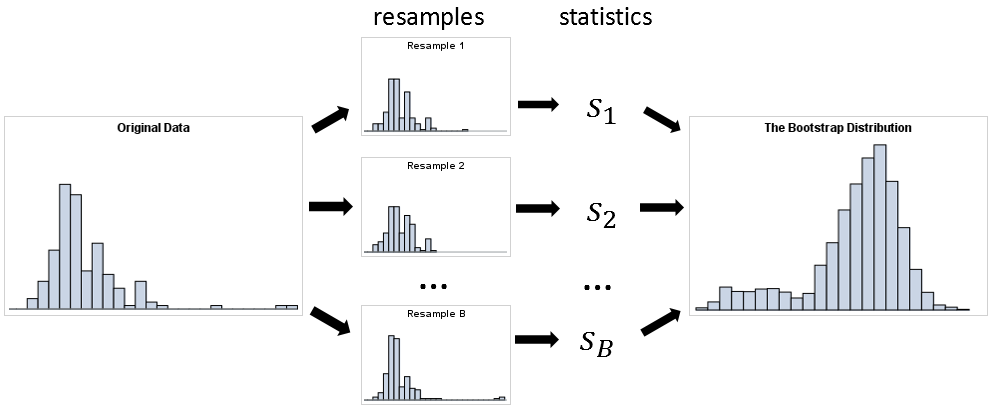
Let’s revisit our quiz-times example, and using boot-strapping to estimate the sampling distribution of the maximum quiz time:
Imagine we collected data from a single class of 100 students who had an average quiz-completion time of 5min +/- 1min:
Sample size \({n = 100}\)
Mean \({\mu = 5}\)
Standard deviation \({\sigma = 1}\)
sample_mean = 5
sample_sd = 1
num_students = 100
np.random.seed(0)
finishing_times = np.random.normal(loc=sample_mean, scale=sample_sd, size=num_students)
print(
f"Average finishing time: {finishing_times.mean():.2f} +/- {finishing_times.std():.2f}"
)
Average finishing time: 5.06 +/- 1.01
How much should we trust this sample mean estimate? How can we estimate our sampling error?
We start by drawing a bootstrapped sample of size \(n\) from the data:
# Notice replace = True
sample = np.random.choice(finishing_times, size=num_students, replace=True)
We compute the statistic of interest on this sample (max)
sample_max = sample.max()
We repeat steps 2-3 1000 times to build up the boot-strapped distribution of the max
boot_maxes = []
for i in range(10000):
this_boot_max = np.random.choice(
finishing_times, size=num_students, replace=True
).max()
boot_maxes.append(this_boot_max)
# Convert it to numpy array to make it easier to work with
boot_maxes = np.array(boot_maxes)
plt.hist(boot_maxes)
We can calculate summary statistics over this bootstrapped distribution to get a sense of the variability across our estimates of the max:
# Calculate the mean and standard deviation
boot_mean, boot_sd = boot_maxes.mean(), boot_maxes.std()
Finally we can visualize the boostrapped distribution along with its mean and standard deviation:
# Plot it
plt.hist(boot_maxes, bins=5)
# Add the mean
plt.axvline(boot_mean, color="red", label="Mean")
# Create error band for SD
x_min, x_max = boot_mean - boot_sd, boot_mean + boot_sd
y_min, y_max = plt.gca().get_ylim() # Get the y-axis limits of the histogram
plt.fill_betweenx(
[y_min, y_max], x_min, x_max, color="red", alpha=0.2, label="1 SD range"
)
plt.xlabel("Max finishing time")
plt.ylabel("Count")
plt.title(
f"Bootstrap distribution of max finishing time\nMean: {boot_mean:.2f}, SD: {boot_sd:.2f}"
);
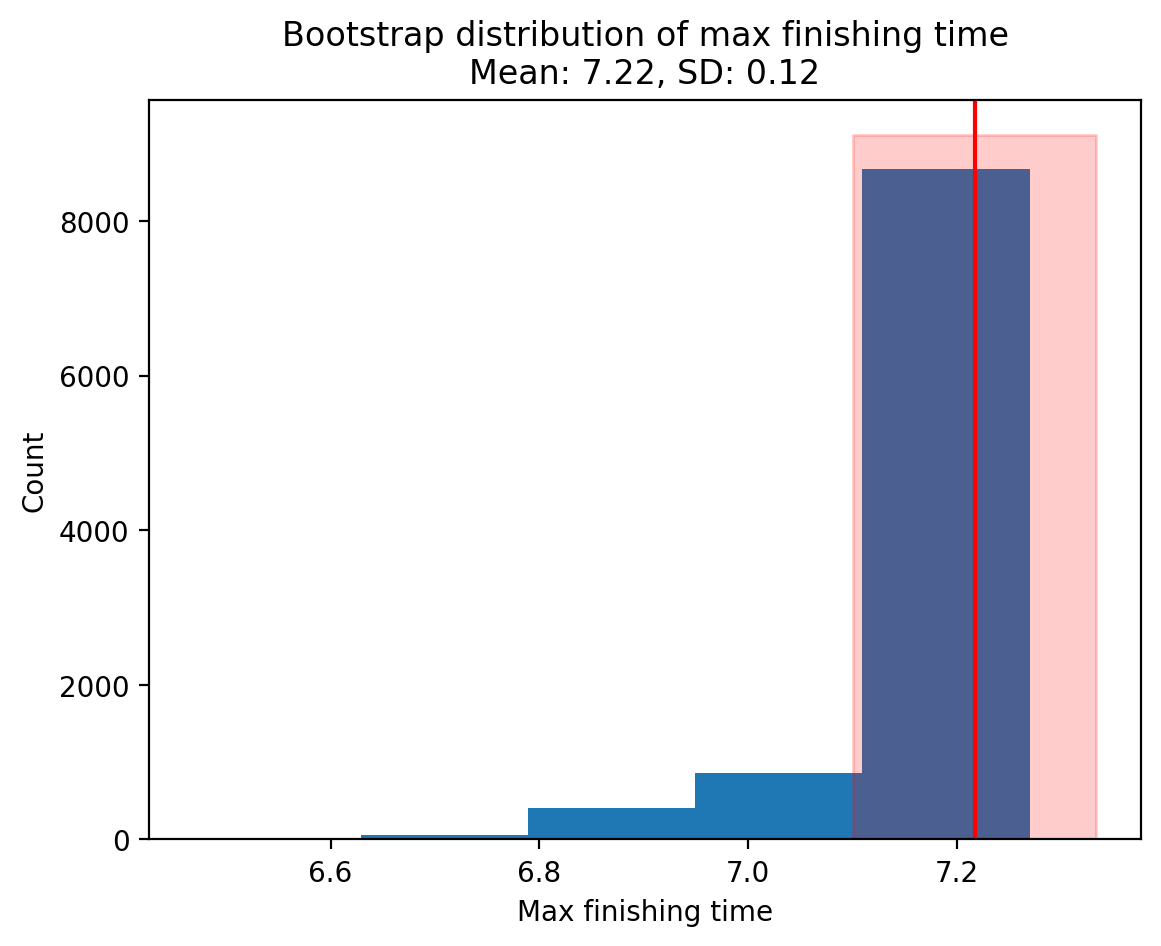
This distribution reflects the max quiz-time from hypothetical samples generated using the sample data we have at hand. It’s distribution gives us a sense of how much variability we should expect for our max quiz-time, were we to have collected another dataset of the same size.
If our estimate bounces around a lot (wide bootstrapped distribution), we ought to trust it less because we can’t be sure that the max estimate from our sample is representative of the max quiz time of the population! In this case we can always collect a larger sample size to try to get a better estimate of the statistic we want, i.e. the max.
On the other hand, even if our estimate doesn’t bounce around a lot (narrow bootstrapped distribution), but it overlaps meaningfully with 0, we might consider that we can’t reliably tell if our estimate is actually different than 0.
More formally:
Standard Deviation gives us this spread for a single sample.
Standard Error gives us the spread across hypothetical samples we didn’t collect
Standard Error = Standard Deviation of the sampling distribution (our bootstrapped distribution!)
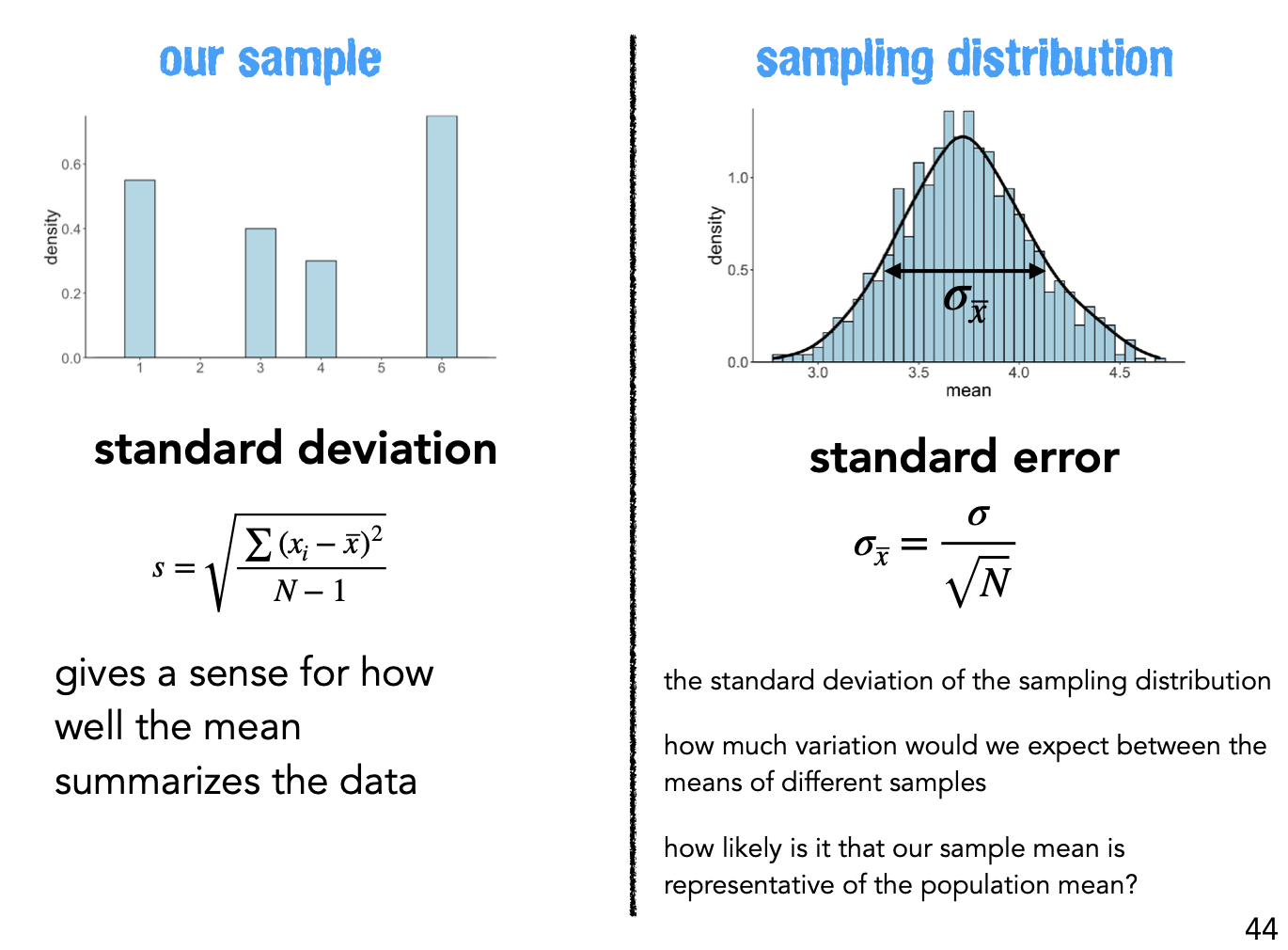
Standard Error implies that the quality of our measurements involve 2 factors
Population variability <- we can’t control this or easily know what it is ahead of time
Size of any given sample <- larger samples give us more certainty about what we’re estimating
At the same time it highlight how the utility of larger samples diminishes as sample size increases.
Doubling a sample size, only increases the quality of our estimate by a factor of \(\sqrt{2}\)!
Confidence Intervals#
We can further formalize the idea of certainty given some “threshold” we think is meaningful for our statistical question.
For example, for some questions we might be ok with being very uncertain, as long as we feel like our estimate reflects what is likely to be true for 95% of such hypothetical samples. For others, we may want a more precise value, at the expense of capturing only 80% of such hypothetical samples.
Formally, we refer to these as confidence intervals for our estimates. This is a range of values that we expect to contain the true value of the statistic we want to estimate X% of the time. And by X% of the time we specifically mean, in X% of hypothetical samples with their own uncertainty.
For example, if we have a 95% confidence interval of [2.5, 4.5] for the max quiz-time, we expect that 95% of our bootstrapped samples will contain the true value of the max quiz-time within their confidence intervals.
Concretely, if we bootstrapped 20 samples and calculated their confidence intervals, we expect that 19 of the 20 samples will contain the true value of the max quiz-time within their own confidence intervals.
Note If you want to see this more interactively, we recommend checking out The Dance of the p-values by Geoff Cumming
We manually calculate our 95% confidence intervals in a pretty simple way: just by percentile thresholding
np.percentile(boot_maxes, [2.5, 97.5])
array([6.89588918, 7.26975462])
But this makes some strong assumptions about the shape of the bootstrapped distrubtion - namely that it’s symmetric and normal-shaped.
In practice, we want to use more advanced methods that account for the bias and skew of the bootstrapped distribution without assuming any shape.
Most commonly, we use BCa (bias-corrected and accelerated) CIs, which specifically account for this. Fortunately for us, we don’t need to keep writing for loops and calculate this manually.
We’re going to use the awesome scipy library and its bootstrap function to do this for us, this time calculating the median quiz time:
# Import it
from scipy.stats import bootstrap
bootstrap?
np.random.seed(0) # for reproducibility
# bootstrap() expects a *sequence* or arrays as input
# since only have one array, we can turn it into a sequence
# by wrapping it in a tuple
data = (finishing_times,) # wrap it in a tuple
result = bootstrap(
data, statistic=np.median, n_resamples=1000, confidence_level=0.95, method="BCa"
)
result?
Type: BootstrapResult
String form: BootstrapResult(confidence_interval=ConfidenceInterval(low=4.816445657080908, high=5.327840624247 <...> 5.15494743, 5.13651324, 5.06651722, 5.09153872, 5.09671466]), standard_error=0.11268765299144144)
File: ~/miniconda3/envs/201b/lib/python3.11/site-packages/scipy/stats/_resampling.py
Docstring:
Result object returned by `scipy.stats.bootstrap`.
Attributes
----------
confidence_interval : ConfidenceInterval
The bootstrap confidence interval as an instance of
`collections.namedtuple` with attributes `low` and `high`.
bootstrap_distribution : ndarray
The bootstrap distribution, that is, the value of `statistic` for
each resample. The last dimension corresponds with the resamples
(e.g. ``res.bootstrap_distribution.shape[-1] == n_resamples``).
standard_error : float or ndarray
The bootstrap standard error, that is, the sample standard
deviation of the bootstrap distribution.
The output of bootstrap is a special scipy object called a BootstrapResult. It doesn’t really matter that we haven’t seen this type of object before, because we can still access it’s attributes using . notation.
For example, we can plot the bootstrapped distribution easily:
plt.hist(result.bootstrap_distribution);
plt.title('Bootstrapped distribution');
plt.xlabel('Median Quiz Time');
plt.ylabel('Count');
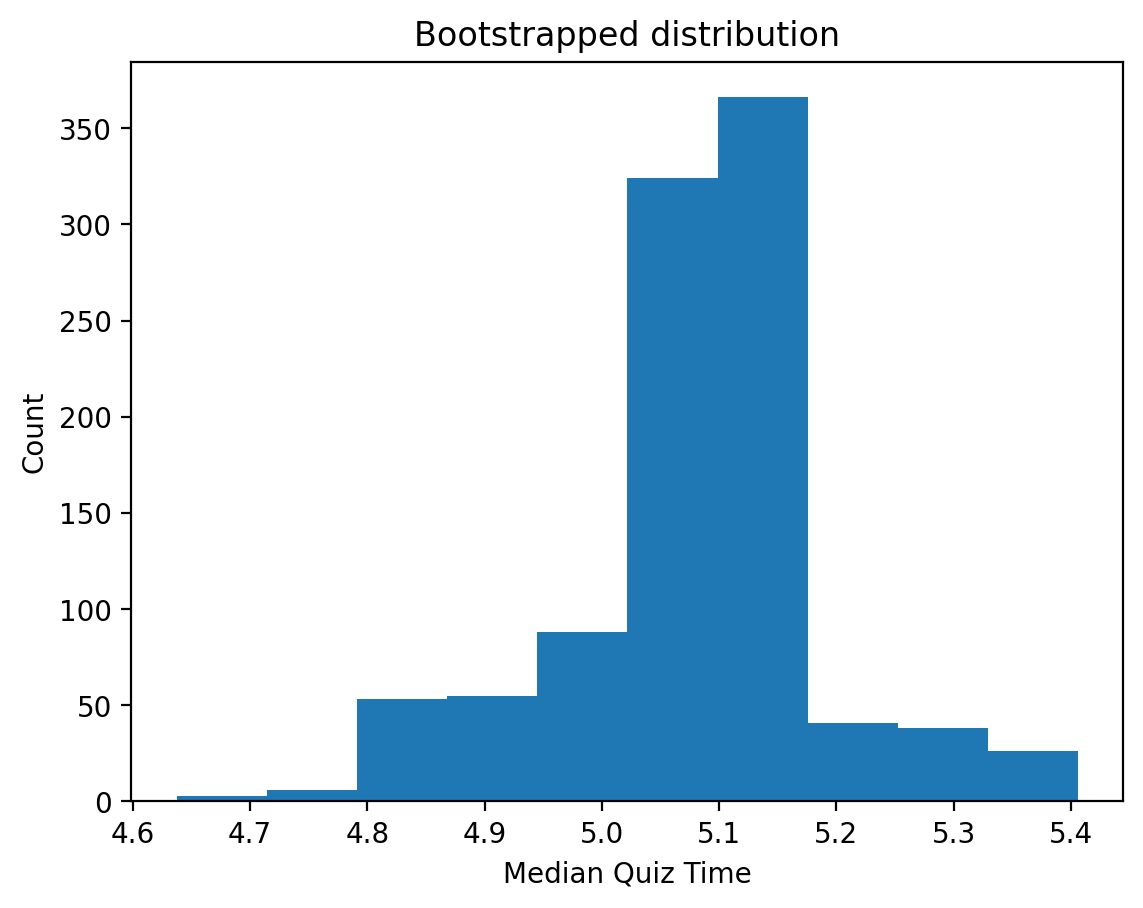
bootstrap also already computes confidence intervals for us:
result.confidence_interval
ConfidenceInterval(low=4.816445657080908, high=5.327840624247037)
Let’s visualize the bootstrap distribution and overlay the confidence intervals:
# Calculate the mean
scipy_boot_mean = result.bootstrap_distribution.mean()
# Plot it
plt.hist(result.bootstrap_distribution)
# Add the mean
plt.axvline(scipy_boot_mean, color="red", label="Mean")
# Create error band for CIs
x_min, x_max = result.confidence_interval
y_min, y_max = plt.gca().get_ylim() # Get the y-axis limits of the histogram
plt.fill_betweenx(
[y_min, y_max], x_min, x_max, color="red", alpha=0.2, label="1 SD range"
)
plt.xlabel("Max finishing time")
plt.ylabel("Count")
plt.title("Bootstrapped distribution");
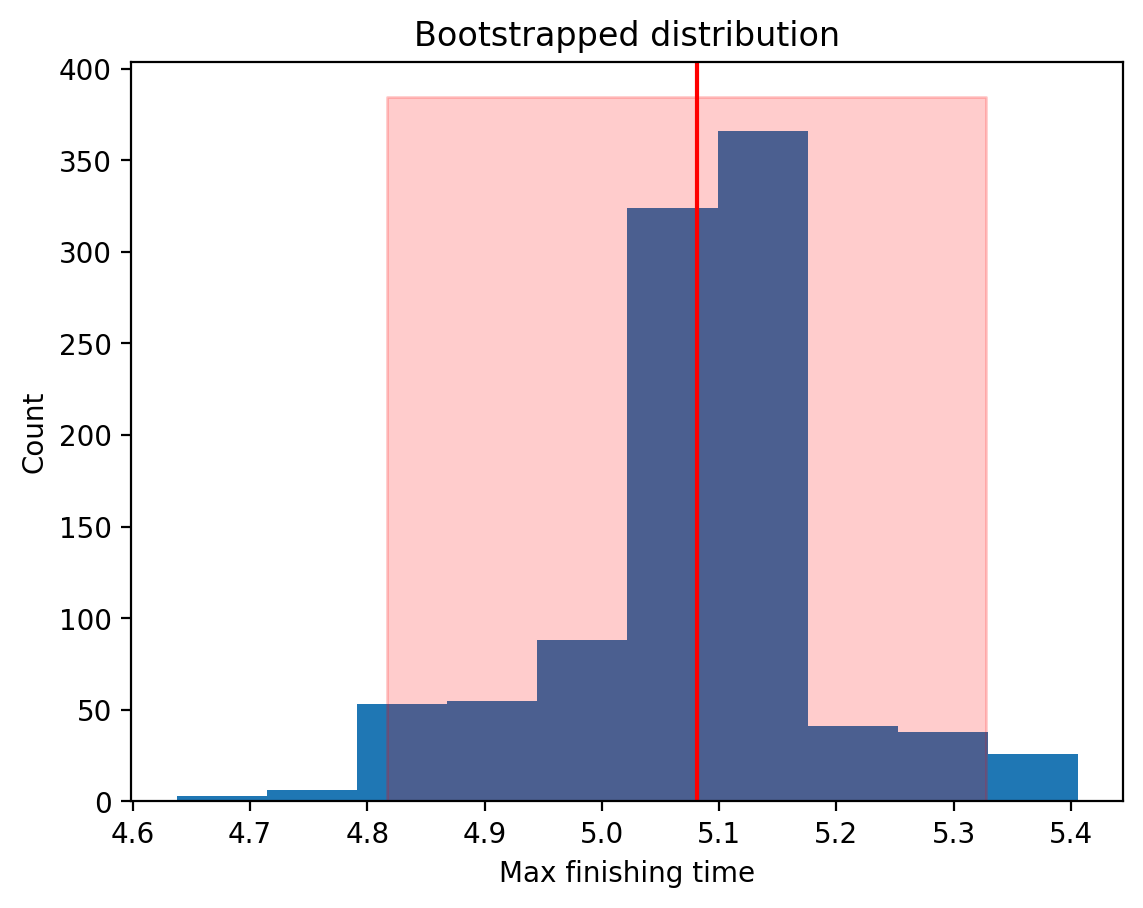
Checking out the sampling#
And we can also verify that the Standard Error it calculated is equal to the Standard Deviation of the bootstrapped distribution:
result.standard_error == result.bootstrap_distribution.std(ddof=1)
True
Notice the ddof = 1 above. This allow us to control the correction factor for our degrees of freedom in the calculation of the standard deviation. The default value is ddof=0, which means that the standard deviation is calculated with no correction, assuming we’re measuring the whole population.
When we set ddof=1, the standard deviation is corrected for the fact that we’re using another estimate (the sample mean) or “consuming a degree of freedom” in order to calculate the standard deviation.
Intuition for degrees-of-freedom#
Intuitively we can think about degrees-of-freedom (dof) as representing the number of values in a calculation that are free to vary while still satisfying any constraints imposed on the data. More generally in statistics, we keep track of this number to adjust calculations and account for the fact that we’re often using estimates of parameters to estimate other parameters.
In this case, we’re using the sample mean to calculate our sample standard deviation. If our estimate of the mean changes, so does our estimate of the standard deviation. In other words, our esimate of the mean is constraining how free-ly our estimate of the standard deviation can bounce around!
This way of thinking about dof as the “freedom of movement” will make more sense when we get into models and model parameters. You should get the sense that it’s reflecting a notion of “independence” among the quantities we’re estimating.
Permutation: Re-sampling without replacement#
In addition to the uncertainty of our estimate, we are also often interested in the probability of observing this estimate under random conditions.
Permutation also referred to as randomization or shuffling allows us to resample our data in a way that gives us an answer to this question!
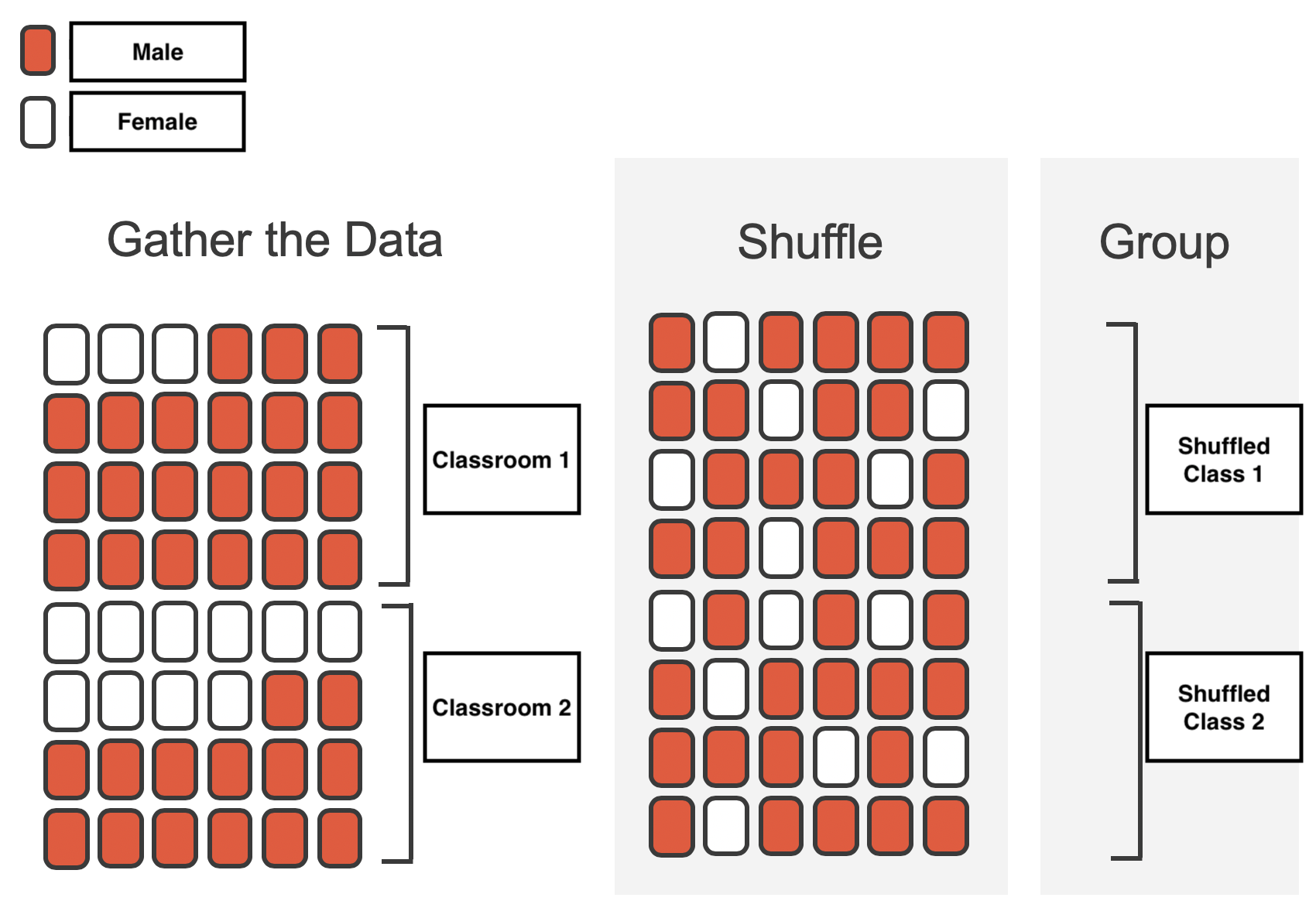
It’s a bit more intuitive to consider this when we’re comparing 2 estimates, so let’s extend our quiz example to a second classroom that doesn’t allow student to bring their laptops to class.
We’re interested in whether having/not-having your laptop affects the quiz-times of each classroom, in other words, the difference in means between the two classes:
class_1_mean = 5
class_2_mean = 5.5
num_students_per_class = 100
np.random.seed(0)
class_1 = np.random.normal(loc=class_1_mean, size=num_students)
class_2 = np.random.normal(loc=class_2_mean, size=num_students)
observed_difference = class_2.mean() - class_1.mean()
print(f"Observed difference (minutes): {observed_difference:.2f}")
Observed difference (minutes): 0.52
How would we approach this with permutation? In general we want to randomize the exchangeable observations in our data. Because each student is only in one class, we can shuffle the class labels for each student and then re-compute the quiz time for each shuffled class:
both_classes = np.concatenate((class_1, class_2))
shuffled_classes = np.random.permutation(both_classes)
class_1_shuffled = shuffled_classes[: len(class_1)]
class_2_shuffled = shuffled_classes[len(class_1) :]
shuffled_diff = class_2_shuffled.mean() - class_1_shuffled.mean()
print(f"Shuffled difference (minutes): {shuffled_diff:.2f}")
Shuffled difference (minutes): 0.04
That looks much smaller that the observed difference, but what if we shuffled differently?
shuffled_classes = np.random.permutation(both_classes)
class_1_shuffled = shuffled_classes[: len(class_1)]
class_2_shuffled = shuffled_classes[len(class_1) :]
shuffled_diff = class_2_shuffled.mean() - class_1_shuffled.mean()
print(f"Shuffled difference (minutes): {shuffled_diff:.2f}")
Shuffled difference (minutes): 0.32
Similar to bootstrapping, we can repeat this process many times, to build up a distribution of shuffled mean differences:
permuted_diffs = []
for _ in range(1000):
# Shuffle the combined data
shuffled_classes = np.random.permutation(both_classes)
# Split into two groups
class_1_shuffled = shuffled_classes[: len(class_1)]
class_2_shuffled = shuffled_classes[len(class_1) :]
# Calculate the difference in means for this permutation
shuffled_diff = class_2_shuffled.mean() - class_1_shuffled.mean()
# Store it
permuted_diffs.append(shuffled_diff)
permuted_diffs = np.array(permuted_diffs)
plt.hist(permuted_diffs);
plt.xlabel("Difference in means");
plt.ylabel("Count");
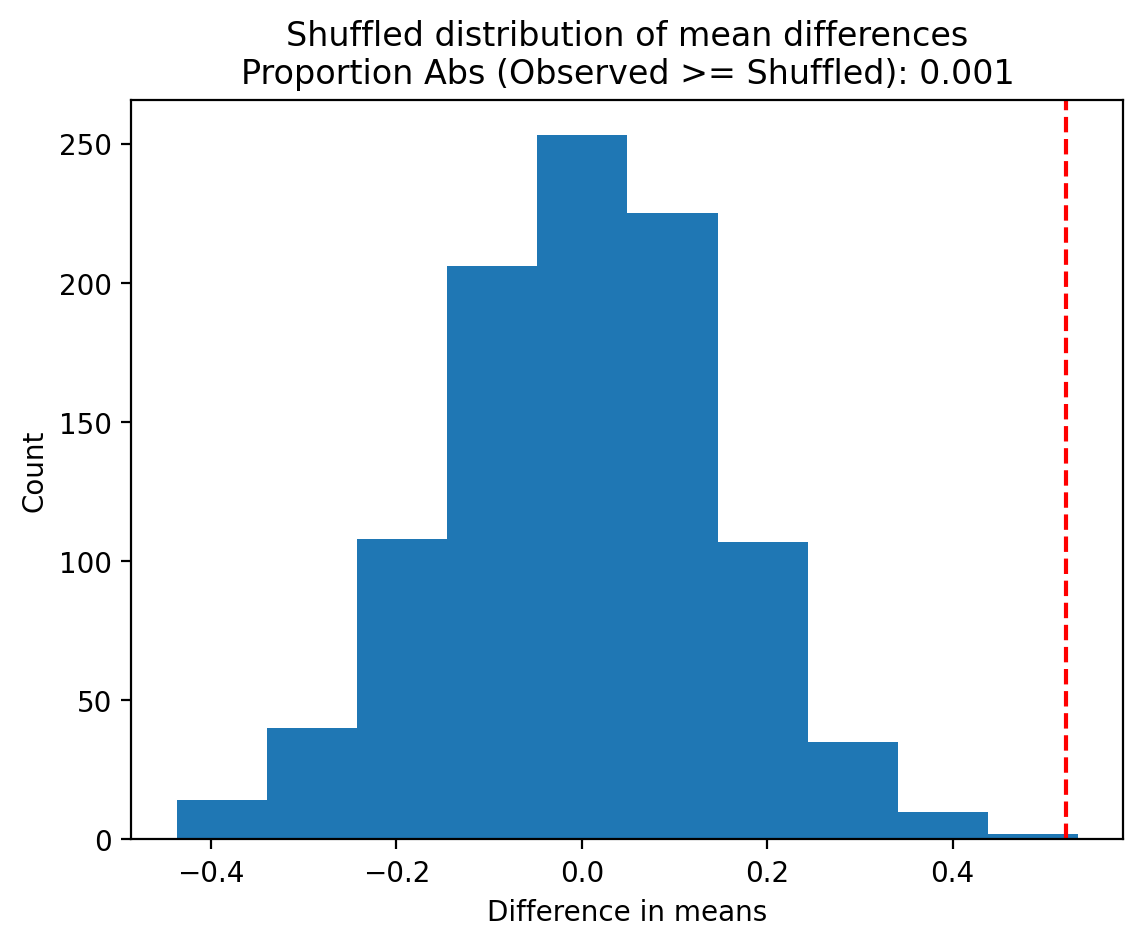
plt.title("Shuffled distribution of mean differences");
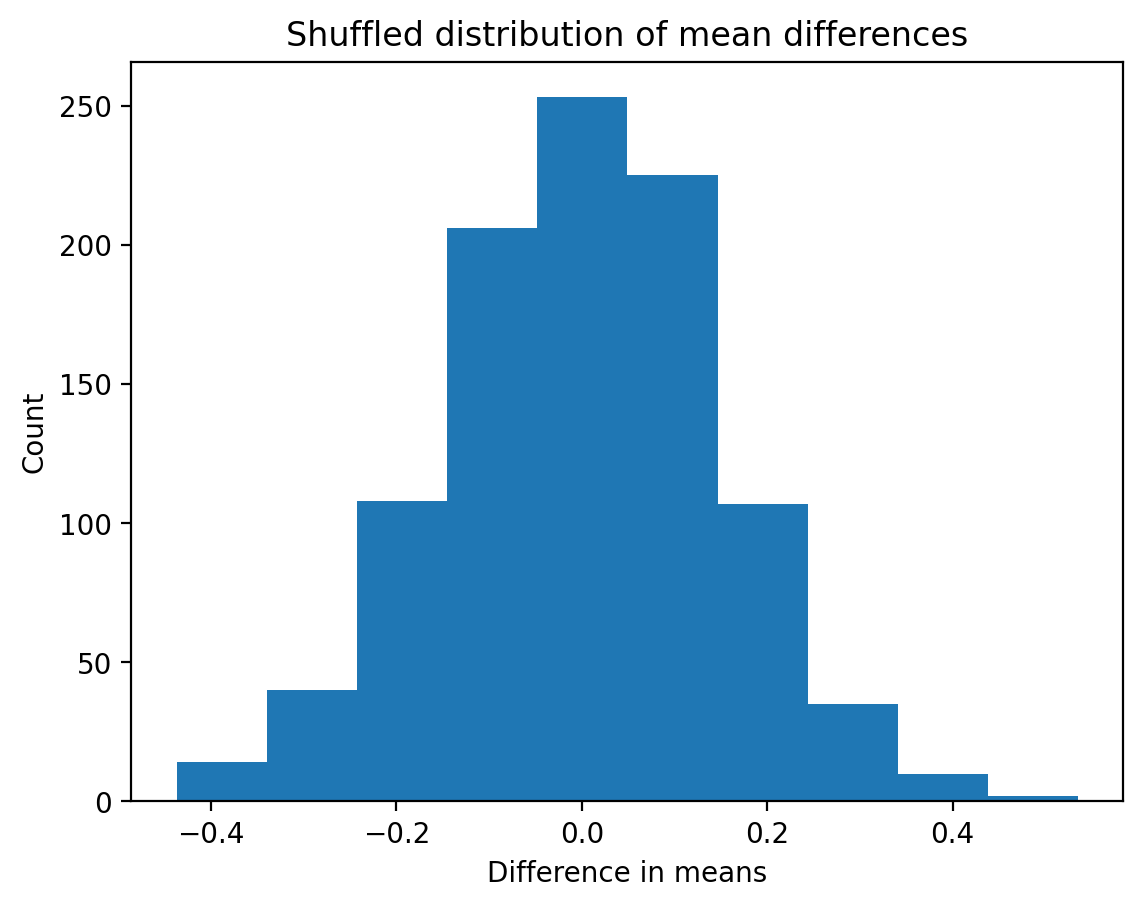
If you’ve ever wondered what a null distribution is, you’re looking at one! Permutation allows us to create a null distribution for any statistic.
This distribution reflects the values we think the statistic could have in a hypothetical random world, where random is specifically tied to the factor we think matters for that statistic: in this case which class a student was in.
We can return to our original question by asking: how often do we see our observed estimate in this randomized distribution?
permuted_p = np.mean(permuted_diffs >= observed_difference)
And then visualize our observed statistic against this distribution:
plt.hist(permuted_diffs);
plt.axvline(observed_difference, color="red", linestyle="--");
plt.xlabel("Difference in means");
plt.ylabel("Count");
plt.title(f"Shuffled distribution of mean differences\nProportion Abs (Observed >= Shuffled): {permuted_p}");
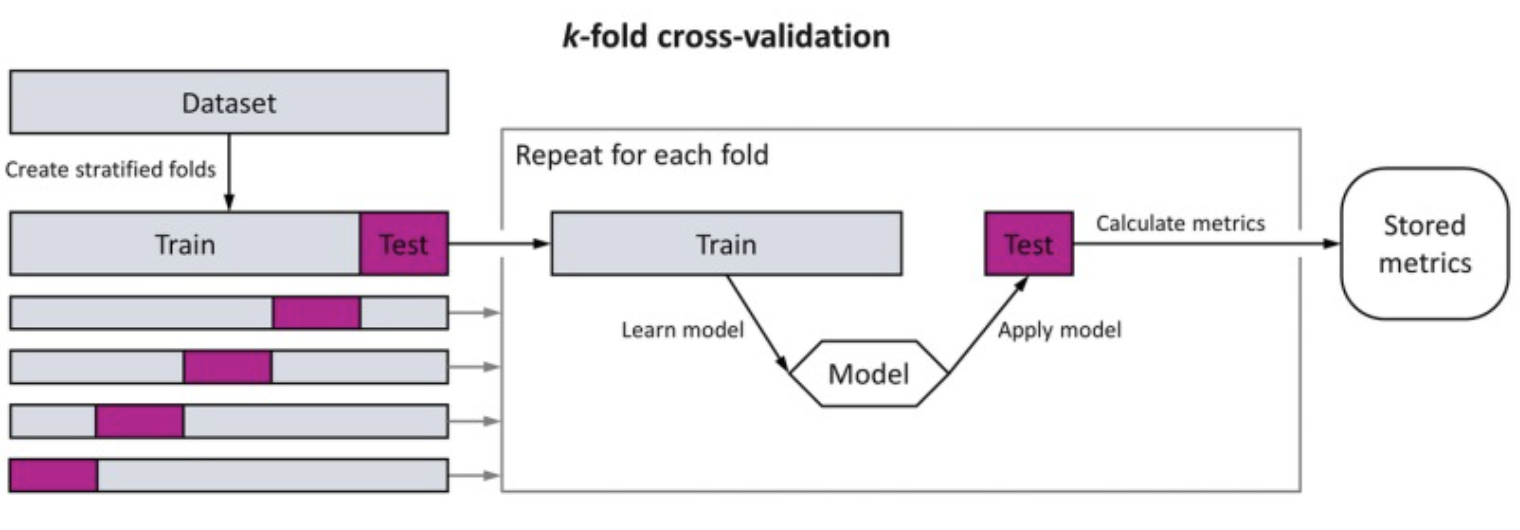
Cross-validation#
Our final resampling method takes up back to the Two Cultures of statistical modeling: explanation and prediction.
We’ve seen how bootstraping can give us a sense of uncertainty about our estimate (sample mean of a class).
But another notion of uncertainty we can think about is how good is the mean at predicting an unobserved student’s quiz time?
Remember from last week - that the mean as an estimator minimizes the SSE (sum of squared errors).
We can convert this value to our average error on the original scale of the data by taking the square-root of the average error (RMSE: root mean squared error):
RMSE = np.sqrt(np.mean((finishing_times - finishing_times.mean()) ** 2))
print(f"Root Mean Squared Error: {RMSE:.6f} minutes")
Root Mean Squared Error: 1.007882 minutes
This tells us that by using the mean as a proxy for any single observation (single student’s quiz time), we’re wrong by approximately 1 minute relative to their true quiz time.
But what we really want to know is how wrong we are for students we did not observe! In other words, how well does our observed mean generalize to the population of all students?
We simulate this via cross-validation or out-of-sample testing. We’ll do this by splitting our observations into random splits or folds - one to estimate the mean, and one to evaluate how well the mean generalizes to new students - and then repeat this process with more random splits:
np.random.seed(0) # For reproducibility
# Number of splits/folds for cross-validation
k = 5
n = len(finishing_times)
# Generate indices for k folds
indices = np.arange(n)
# Randomize them so each fold has a different split of students
np.random.shuffle(indices)
# Split indices into k approximately equal-sized folds
folds = np.array_split(indices, k)
# Cross-validation for RMSE
rmse_values = []
for i in range(k):
# Use one fold to estimate mean
# and the other to test how well it generalizes
test_indices = folds[i]
train_indices = np.setdiff1d(indices, test_indices)
observed_students = finishing_times[train_indices]
unobserved_students = finishing_times[test_indices]
# Step 2: Estimate mean using observed students
train_mean = np.mean(observed_students)
# Step 3: Calculate RMSE on unobserved students
rmse = np.sqrt(np.mean((unobserved_students - train_mean) ** 2))
rmse_values.append(rmse)
print(f"RMSE per fold: {rmse_values}")
RMSE per fold: [0.9861208571652235, 1.0251420562350702, 1.0531110065581861, 1.1192749932421364, 0.8538980372557612]
Then we can summarize our out-of-sample RMSE across out folds:
# Average RMSE across folds
avg_rmse = np.mean(rmse_values)
print(f"Cross-validated RMSE: {avg_rmse:.6f}")
Cross-validated RMSE: 1.007509
In this case the RMSE for unobserved students is slightly worse than the observed students. This is what we expect since the unobserved students, were not used to estimate the sample mean.
At the same time, they’re not that different, because we generated our classroom assuming all students come from the same population with the same mean!
We’ll be revisiting cross-validation more later in the course, and in practice we have many tools to make this easier for us and split the data up in more interesting ways. We’ll leave it as an exercise to you to explore the scikit-learn library which has many handy functions to perform cross-validation, such as:
train_test_split: Splits data into training and testing setskfold: Splits data into k-folds for cross-validationstratified_kfold: Splits data into k-folds for cross-validation with stratified sampling
Challenge#
Your turn to try these methods out with the following challenge!
Imagine you’re conducting research at a wildlife preserve to study the feeding behavior of a rare species of red pandas.

Since this is a new species, the preserve wants to know how much the animals are eating in order to ensure both their health and enough supplies.
You’ve been given data on the amount of food (in kg) consumed per day by individual foxes (100 total) during a one-week observation period in a file called pandas_food.npy.
Use these data to complete the following tasks:
Simulation#
Use Monte Carlo simulation to simulate and compare the sampling distribution of pandas’ mean food consumption under 2 different assumptions:
That mean food consumption is normally distributed
That mean food consumption is uniformally distributed
Which of these assumptions is more likely to be true? Why?
# Your code here
panda_food = np.load('panda_food.npy')
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(0)
pandas_food = np.load('panda_food.npy')
plt.hist(pandas_food);
norm_means = [
np.mean(np.random.normal(loc=pandas_food.mean(), size=pandas_food.size))
for _ in range(1000)
]
plt.hist(norm_means);
uniform_means = [
np.mean(np.random.uniform(pandas_food.min(), pandas_food.max(), size=pandas_food.size))
for _ in range(1000)
]
plt.hist(uniform_means);
Bootstrap#
Use bootstrapping (re-sampling with replacement) to estimate the sampling distribution of min, max, mean, and median of the data.
For each estimate, provide the 95% confidence intervals for the boostrapped estimate.
Can you interpret each statistic and CI so the animal preserve staff can understand how to think about them?
Hint: check out the bootstrap function in scipy.stats
# Your code here
# Your code here
from scipy.stats import bootstrap
data = (pandas_food,)
b_mean = bootstrap(data, statistic=np.mean, n_resamples=1000)
b_median = bootstrap(data, statistic=np.mean, n_resamples=1000)
b_min = bootstrap(data, statistic=np.min, n_resamples=1000)
b_max = bootstrap(data, statistic=np.max, n_resamples=1000)
b_mean.confidence_interval
b_median.confidence_interval
b_min.confidence_interval
b_max.confidence_interval
ConfidenceInterval(low=5.9250792122996385, high=7.093199750016277)
ConfidenceInterval(low=5.921104136467661, high=7.048691156152495)
ConfidenceInterval(low=0.8940203683318426, high=2.038407063552146)
ConfidenceInterval(low=20.0, high=22.0)
Permutation#
The preserve is also really concerned with how much natural predators of red pandas, snow leopards are eating, especially if they’re eating more than the pandas.
They’ve been similarily tracking their food intake over the same week in a file called leopard_food.npy. Using this file along with the pandas_food.npy file, run a permutation to compare the mean difference in food intake between pandas and leopards.
Can you explain what you found to the animal preserve staff to help answer their question?
# Your code here
leopard_food = np.load('leopard_food.npy')
from scipy.stats import permutation_test
def mean_diff(a, b):
"""Mean A < Mean B"""
return b.mean() - a.mean()
result = permutation_test([pandas_food, leopard_food], statistic=mean_diff)
plt.hist(result.null_distribution);
plt.axvline(result.statistic, color='r');
plt.title(f"Null distribution of Leopard > Pandas\nMean Diff: {result.statistic:.3f}; p = {result.pvalue:.3f}");
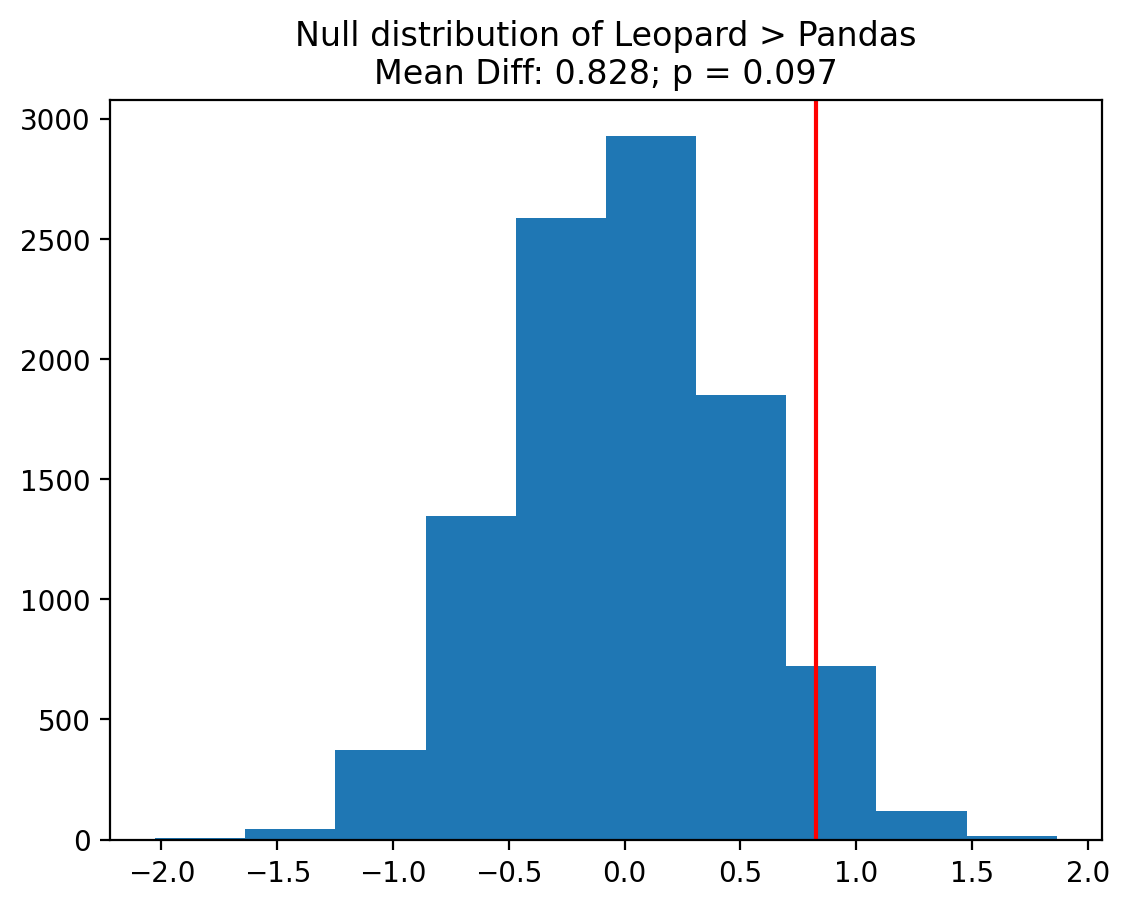
leopard_food.mean() - pandas_food.mean()
0.8278437963840481
Cross-validation#
One of the longest-employed members of the staff has observed that there might be a lot of variability in food consumption across members of each species (i.e. across pandas or across leopards). Having taken a statistics course many years ago, they’re wondering if the mean is a good estimate of food intake for each species or the median might be more useful.
Using cross-validation, can you compare the mean and median as estimators of food intake for each species?
Feel free to use any type of data-splitting scheme you like (e.g. k-fold, randomized, etc.)
Hint: You can evaluate the mean by calculating the RMSE (root mean squared error) and the median by calculating the MAE (mean absolute error).
# Your code here
# Setup
from sklearn.model_selection import KFold
# k-Fold Cross-Validation
k = 5
kf = KFold(n_splits=k, shuffle=True, random_state=0)
# RMSE error using each estimate
rmse_mean, rmse_median = [], []
# MAE error using each estimate
mae_mean, mae_median = [], []
# He're we're estimating across both animals, but you can do it within animal too
data = np.concatenate((pandas_food, leopard_food))
for train_index, test_index in kf.split(data):
train_data = data[train_index]
test_data = data[test_index]
# Estimate mean and median from training data
train_mean = np.mean(train_data)
train_median = np.median(train_data)
# Calculate RMSE
rmse_mean.append(np.sqrt(np.mean((test_data - train_mean) ** 2)))
rmse_median.append(np.sqrt(np.mean((test_data - train_median) ** 2)))
# Calculate MAE
mae_mean.append(np.mean(np.abs(test_data - train_mean)))
mae_median.append(np.mean(np.abs(test_data - train_median)))
# print(f"Within-sample RMSE: {avg_within_rmse:.4f}")
print("RMSE:")
print(f"\tOut-of-sample (CV) Mean: {np.mean(rmse_mean):.4f}")
print(f"\tOut-of-sample (CV) Median: {np.mean(rmse_median):.4f}")
print("MAE:")
print(f"\tOut-of-sample (CV) Mean: {np.mean(mae_mean):.4f}")
print(f"\tOut-of-sample (CV) Median: {np.mean(mae_median):.4f}")
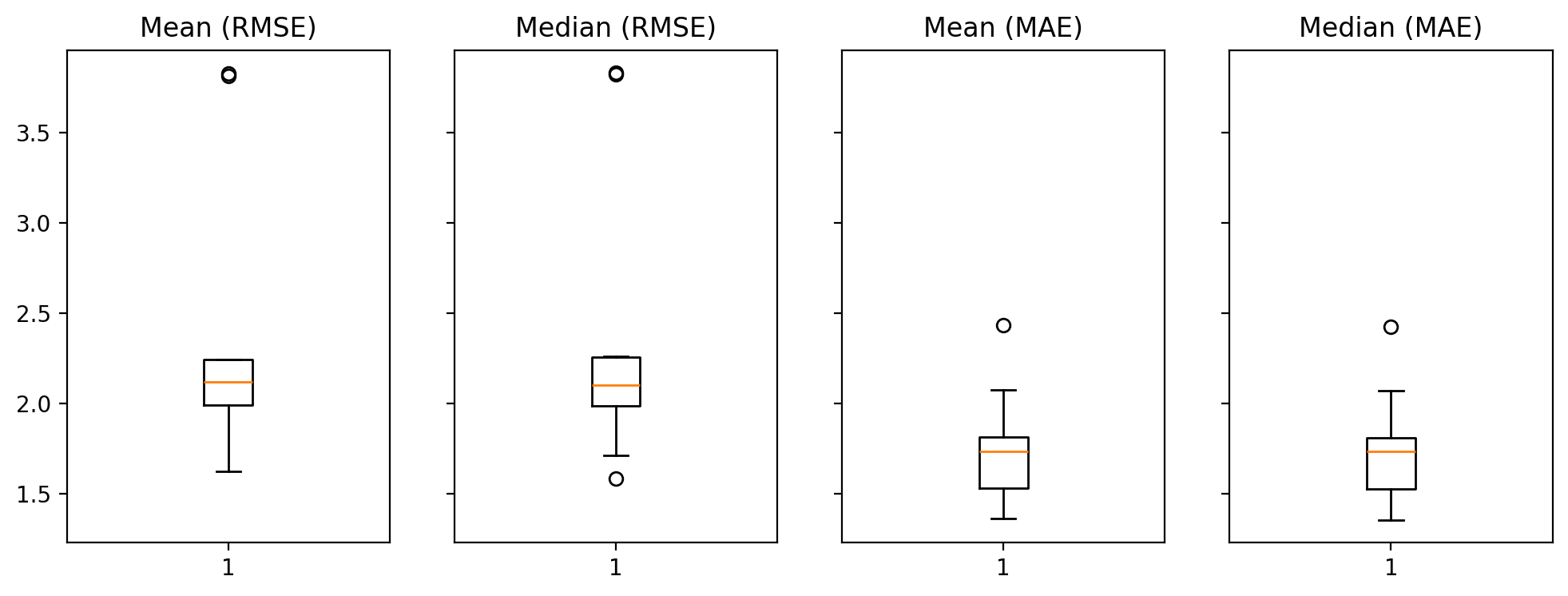
RMSE:
Out-of-sample (CV) Mean: 2.3715
Out-of-sample (CV) Median: 2.3678
MAE:
Out-of-sample (CV) Mean: 1.7530
Out-of-sample (CV) Median: 1.7473
f, axs = plt.subplots(1,4, figsize=(12,4), sharey=True);
metrics = {
"Mean (RMSE)": rmse_mean,
"Median (RMSE)": rmse_median,
"Mean (MAE)": mae_mean,
"Median (MAE)": mae_median,
}
keys = list(metrics.keys())
values = list(metrics.values())
metrics = [rmse_mean, rmse_median, mae_mean, mae_median]
for i, ax in enumerate(axs.flat):
_ = ax.boxplot(values[i]);
_ = ax.set_title(f"{keys[i]}");